9. 回归问题
9.1. MSE & MAE
MSE 假设预估值 \(\boldsymbol{\theta}^{\top}\boldsymbol{x}\) 和真实值 \(y\) 的误差服从标准正态分布,可以推导出 \(p(y|\boldsymbol{x};\boldsymbol{\theta})\) 是正态分布。通过最大似然估计( MLE )可知, 最大化似然概率就是最小化 MSE Loss。
9.2. Weighted Logistics Regression
Youtube DNN 在预估视频观看时长时, 在训练中使用交叉熵损失,然后对于正样本(有点击的样本)用实际观看时长来做加权,负样本(曝光未点击的样本)不变。
推断时使用 \(e^{Wx+b}\) 作为观看时长的估计(这里面假设了点击概率非常小)。
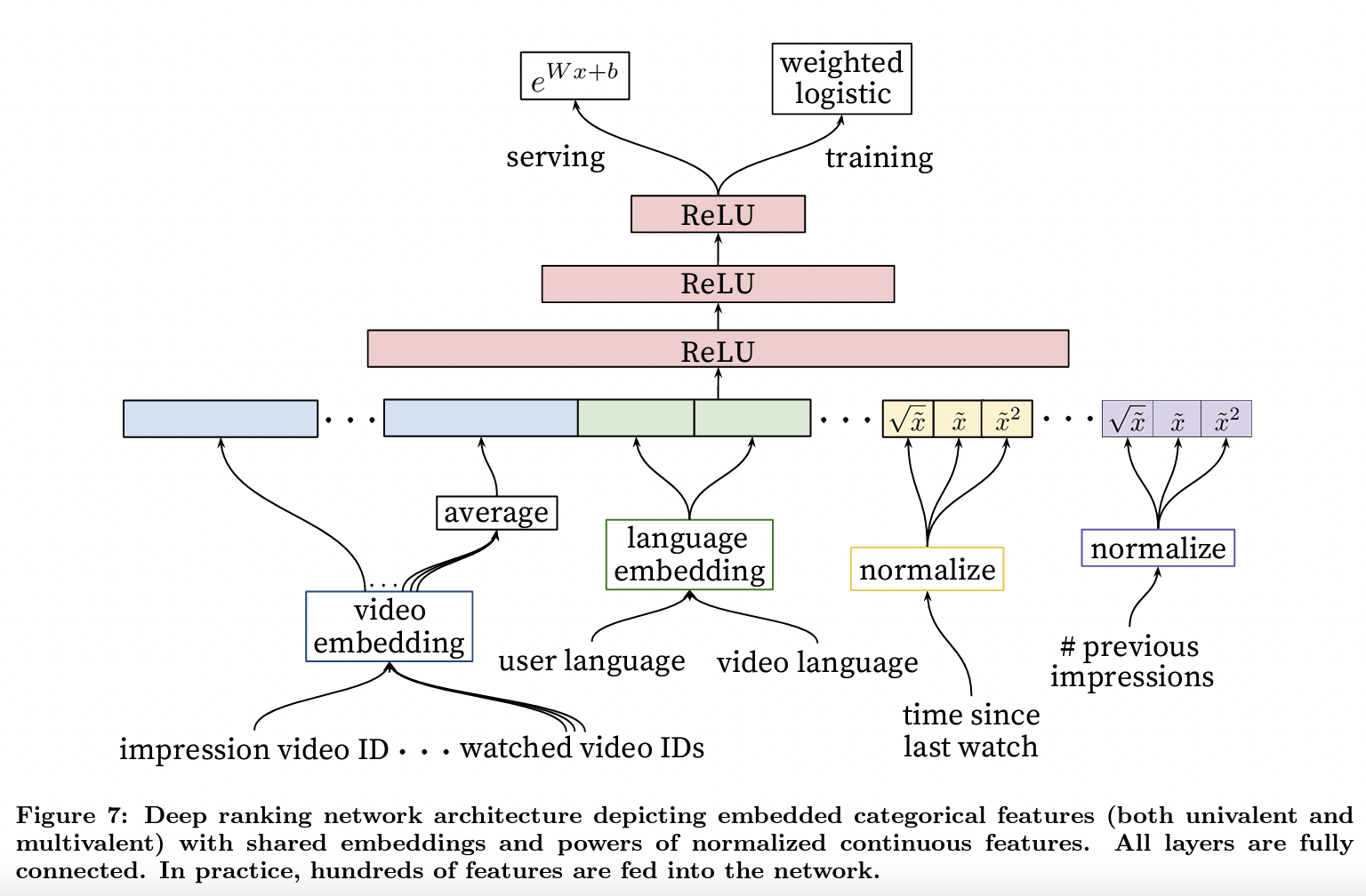
Note
上面的建模是基于曝光样本,还有一种思路是仅用点击样本训练(假设数量为 \(k\) ),这些样本作为正样本的权重也是观看时长,同时再将这些样本复制一遍作为负样本(只改变 label),权重为 1。
9.3. D2Q
分析指出,观看时长主要受两个因素的影响:用户是否对视频感兴趣 & 视频本身的时长。一方面,长度在 100s 以下的视频,其观看时长和本身时长正相关,将视频时长作为输入特征的观看时长预测方法会引入偏置问题;另一方面,随时间推移,视频时长分布极不均匀,且长视频曝光占比会逐渐增大,此时模型训练样本被长视频占据,用户兴趣可能无法有效建模。
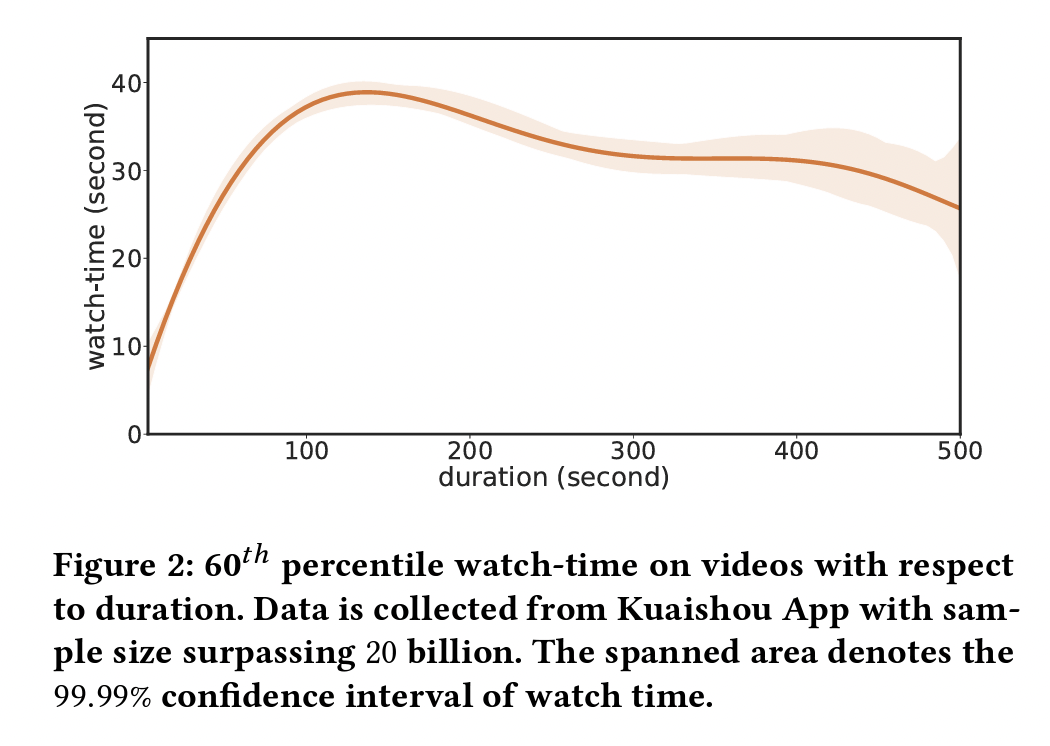
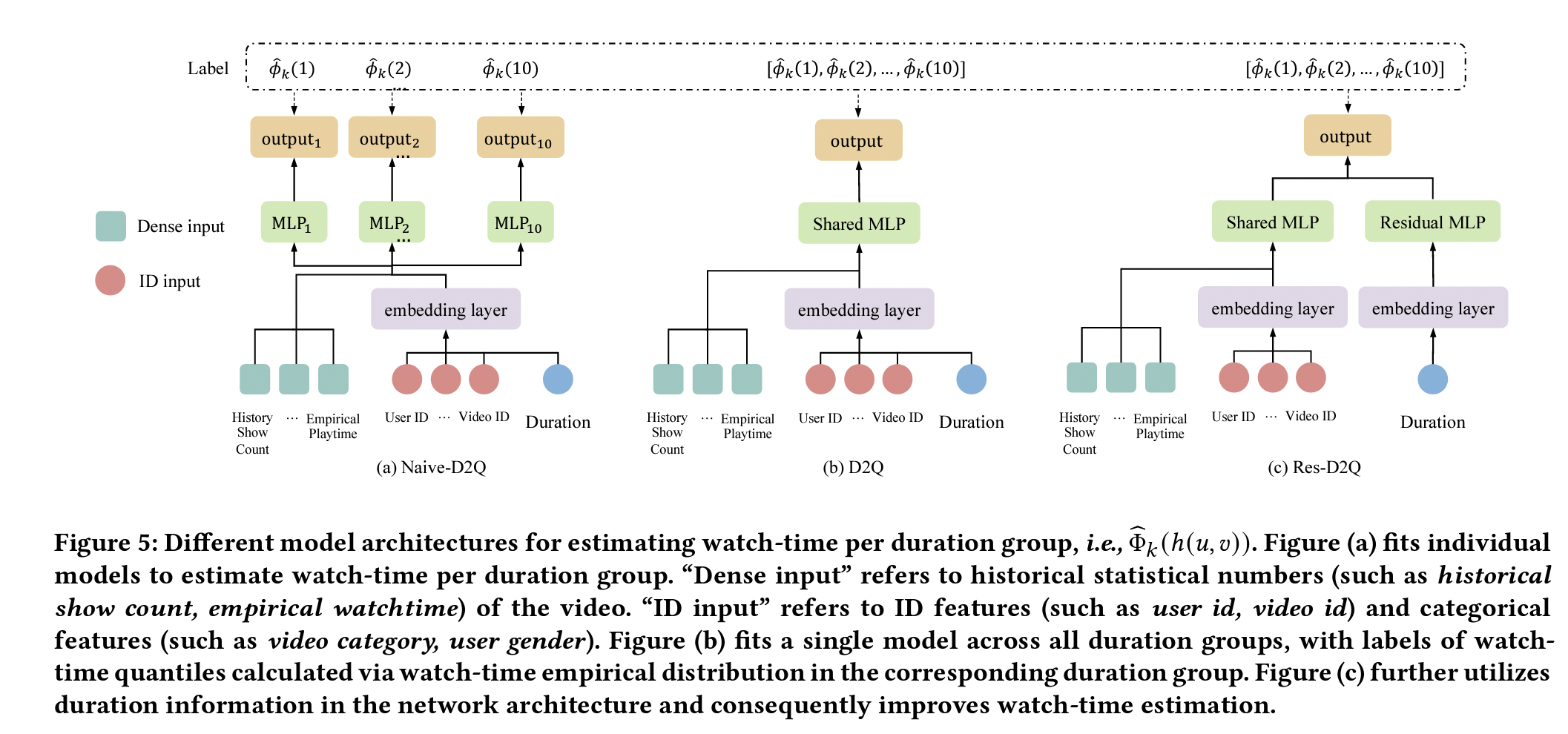
D2Q 首先将数据按视频时长分组(按时长排序,等分成若干个组),然后每个分组学习回归模型去预测观看时长分位数(Watch-Time Quantiles);推断时,将对应分组中预测的分位数映射回时长。
在实际应用中,无法为每一个分组单独预测观看时长,因为模型参数太多,效率低下;但如果在所有分组之间共享模型参数,拟合原始观看时长数值,相当于没有进行数据划分、无法消偏。因此,作者进一步提出将原始观看时长转换为视频时长相关的时长分位数标签, 这样一来,每个分组的参数是共享的,同时每个分组的学习目标的尺度也是统一的。
9.4. Ordinal Regression
OR-CNN 做年龄预测时, 考虑到年龄的连续性特点,用 \(K-1\) 个二分类问题实现顺序的年龄回归。

损失函数(可以为每个分类任务设置不同的权重):
其中 \(\boldsymbol{p}_i \in \mathbb{R}^{(K-1) \times 2},\ \boldsymbol{y}_i \in \mathbb{R}^{K-1}\) ;当 \(\mathrm{Age}[i] > r_k\) , \(y_i^k = 1\) ,反之 \(y_i^k = 0\) ; \(\boldsymbol{p}_i^k\) 经过 Softmax 归一化。
预测年龄是 \(r_q\) , \(q = 1 + \sum_{k=1}^{K-1} f(k)\) ,其中 \(f(k) \in \{0,1\}\) 是每个分类任务的预测结果。
9.5. ZILN
在 LTV (Life-Time Value)预测任务中,数据往往是长尾且稀疏的,比如会有非常多的 0 值,也存在极端大的值。 MSE 无法准确地拟合 0 值,且对于极端大的值非常敏感。
ZILN(Zero-Inflated LogNormal)是一个对数正态参数估计模型,其假设 LTV 服从对数正态分布。
ZILN 需要估计三个参数: \(p,\mu,\sigma\) :

损失函数:
相比于 MSE,在预估值异常大时 \(\mathcal{L}_{\mathrm{Lognormal}}(x;\mu,\sigma)\) 也不会非常大。
预测结果:
9.6. Bucketing With Softmax
对 Label 的值域进行分桶,然后根据每个样本的 Label 把样本分到某个桶里,将任务转换为一个多分类问题,通过 Softmax 损失函数进行训练。
有一个问题是,Softmax 会将所有的桶平等看待。事实上,当 Label 的大小是有意义的,相邻桶之间的 Loss 应该小于不相邻桶之间的 Loss。
9.7. 评估指标
MAE
MSE
排序逆序对
9.8. 参考资料
回归任务里的损失函数
视频播放建模
快手:基于因果消偏的观看时长预估模型
LTV预估的一些思考
加权对数几率回归
年龄估计:Ordinal Regression
Ordinal regression
Deconfounding Duration Bias in Watch-time Prediction for Video Recommendation
A Deep Probabilistic Model For Customer Lifetime Value Prediction
Ordinal Regression with Multiple Output CNN for Age Estimation